1. MLOps란?
- ML 모델이 서비스화 되는 과정에서 관리해야되는 모든 운영적인 부분(ModelOps + DataOps + DevOps)을 관리하기 위한 방법론
- ML의 지속적 배포 및 자동화 파이프라인 구축
- 단순 ML 모델 뿐 아니라 데이터를 수집하고 분석하는 것부터 ML 모델을 학습하고 배포하는 단계까지의 여러 이슈와 반복을 최소화하여 비즈니스 가치를 창출하는 것이 목표이다.
2. ML 시스템의 요소
ML 시스템을 Production 환경에 적용 및 운영하기 위해서는 단순히 좋은 모델만으로 가능한 것이 아니다. 전체 ML 시스템의 운영을 고려하면 모델 학습 자체는 굉장히 작은 부분에 속한다.
모델을 운영하기 위해서는 기반 데이터 및 인프라를 포함한 모든 시스템이 유기적으로 돌아가야 한다.

3. ML 생애주기
MLOps는 ML의 전체 Lifecycle을 관리해야 한다.
- 문제 정의
- Data Extraction(데이터 추출)
- Data Analysis(데이터 분석/탐색): EDA, 데이터 스키마 및 특성 이해
- Data Preparation(데이터 준비): 학습, 검증, 테스트 데이터셋 분할
- Model Training(모델 학습): 다양한 알고리즘 구현 및 하이퍼 파라미터 조정 및 적용
- Model Evaluation(모델 평가)
- Model Validation(모델 검증)
- Model Serving(모델 서빙)
- 온라인 예측을 제공하기 위해 REST API 포함된 마이크로 서비스
- 배치 예측 시스템
- 모바일 서비스의 Embedded 모델 - Model Monitoring(모델 모니터링)

4. DevOps vs MLOps
- DevOps: 소프트웨어 개발 + IT 운영. 소프트웨어 개발 및 배포 과정을 최적화하여 SW 품질 향상과 신속한 배포를 목표로 한다.
- MLOps: DevOps 원칙을 ML 시스템에 적용. ML 시스템 개발 + 운영
- DevOps와 MLOps의 차이
- Testing
일반적인 단위, 통합 테스트 외에 데이터 검증, 모델 품질 평가 등이 추가로 필요 - Deployment
단순 ML 모델을 배포하는 것 뿐만 아니라 새 모델을 재학습하고, 검증하는 과정을 자동화해야 함 - Production
알고리즘 최적화를 통해 최적의 성능을 낼 수 있는 소프트웨어 시스템과 달리 ML 모델은 지속적으로 진화하는 Data Profile 자체만으로 성능이 저하될 수 있다.
즉, 기존 소프트웨어 시스템보다 더 다양한 이유로 성능이 저하될 수 있으므로 데이터의 Summary Statistics를 꾸준히 추적하고 모니터링하여 기대치를 벗어나면 알림을 전송하거나 롤백할 수 있도록 해야한다. - CI(Continuous Integration)
Code와 Component뿐만 아니라 Data, Data Schema, Model에 대해서도 모두 테스트 및 검증해야 한다. - CD(Continuous Delivery)
단일 소프트웨어 패키지가 아니라 ML 학습 파이프라인 전체를 배포해야 한다. - CT(Continuous Training)
ML 시스템만의 속성으로, 모델을 자동으로 학습시키고 평가하는 단계이다.
- Testing
5. ML 파이프라인 구축 목적
- 표준화 및 생상성 향상
- 예측 가능한 품질
- 장애 대응 능력 향상 및 버그 예방
- 변경사항 추적
6. MLOps 성숙도
ML 프로세스 자동화 수준에 따라 ML 시스템의 성숙도를 3가지로 나눌 수 있다.
1. MLOps Level 0: Manual Process
- 모델 수가 적거나 거의 변경되지 않는 경우에 적절함

- 데이터 추출과 분석, 모델 학습, 검증을 포함한 모든 단계가 수동
- ML과 Operation 간 Disconnection
- 데이터 사이언티스트가 모델을 아티팩트로 전달하고 엔지니어가 프로덕션 환경에 배포.
- training serving skew(편향)이 발생할 수 있다.
- Infrequent release iteration
- 새 모델 버전의 배포가 비정기적으로 발생한다.
- No CI/CD
- 변경과 배포가 거의 없으므로 필요하지 않다. (노트북에서 개인적으로 테스트)
- Active performance monitoring의 부재
- low latency로그나 모델의 예측 성능 등을 모니터링 하지 않는다.
- 모델의 성능이 저하되거나 이상동작이 있어도 감지할 수 없다.
1-1. Level 0의 Challenges
- ML 모델은 현실 세계와 상호작용하기 때문에 모델 배포 시 환경 변화에 적응하지 못하여 예측 능력이 떨어질 수 있다.
- 모델의 정확도를 높이려면?
- 프로덕션 환경의 모델 품질 모니터링: 성능 저하 및 모델의 staleness(신선도가 떨어짐)를 감지
- 최신 데이터로 모델 재학습
- 새로운 feature의 추출, 모델 아키텍처, 하이퍼파라미터 등의 새로운 구현을 계속 시도
2. MLOps Level 1: ML pipeline Automation

2-1. Level1의 특징들
- Rapid Experiment
- 실험을 빠르게 반복하고, 전체 파이프라인을 프로덕션으로 빠르게 배포
- 개발환경에서 쓰인 파이프라인이 운영 환경에도 그대로 쓰임 (DevOps의 MLOps 통합에 있어 핵심적인 요소)
- 프로덕션 모델의 CT
- 새로운 데이터를 사용하여 프로덕션 모델이 자동으로 학습
- CD
- 새로운 데이터로 학습되고 검증된 모델이 지속적으로 배포됨
- Level0에서는 학습된 모델만을 배포했담녀 Level1에서는 전체 파이프라인이 배포됨
2-2. CT를 위해 필요한 것들
새로운 데이터를 통해 새로운 모델을 지속적으로 학습하므로, Data validation과 Model Validation이 필수적이다.
Data and Model Validation
- Data Validation
- 데이터 검증에서 실패하면, 신규 모델의 배포를 중지해야 한다. (해당 의사결정도 자동화 되어야 함)
- Data Schema skews: 예상치 못한 데이터가 생성된 경우
- Data Values skews: 데이터의 통계적 속성이 변화되고 있음을 감지하여 모델의 재학습을 트리거한다.
- Model Validation
- 모델이 새로운 데이터로 재학습되면 운영 환경에 반영되기 전에 평가되고 검증되어야 한다.
- 평가 메트릭 생성하여 새로운 모델과 현재 모델을 비교하고 새로운 모델이 기존 모델보다 더 나은 성과를 보이는지, 다양한 세그먼트에서 일관된 성과를 보이는지 검증한다.
- 인프라 및 예측 서비스 API와 호환성 테스트를 완료한다.
Feature Store
Feature Store는 학습과 서빙에 사용되는 모든 Feature들을 모아둔 저장소이다.
대용량 배치 처리와 low latency의 실시간 서빙을 모두 지원할 수 있어야 한다.
Metadata Management
ML 파이프라인의 실행 정보, 데이터 및 아티팩트의 계보 등을 저장한다.
- 실행된 파이프라인의 버전, 시작-종료 시간, 소요시간 등
- 파이프라인의 실행자, 매개변수 인수
- 이전 모델에 대한 포인터 (롤백이 필요할 수 있음)
- 모델 평가 단계에서 생성된 모델 평가 측정 항목
ML pipeline trigger
- 모델을 재학습시키는 파이프라인의 자동화
- 매일, 매주 또는 매월 등의 재학습 빈도 설정
- 모델 성능 저하가 눈에 띄는 경우 모델 재학습 트리거
3. MLOps Level 2: CI/CD pipeline Automation

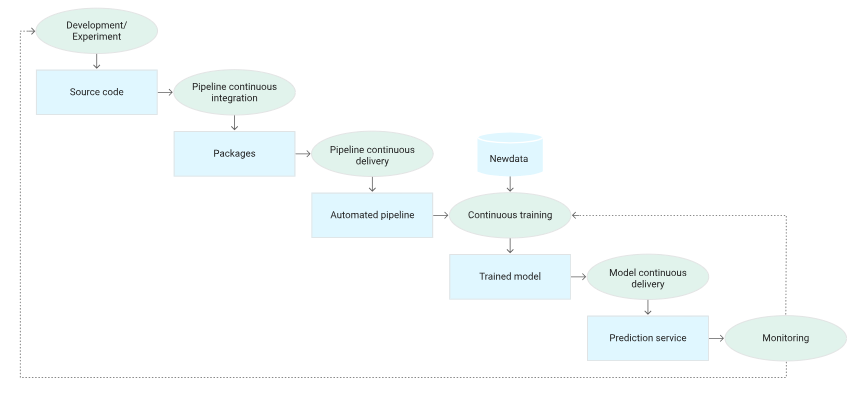
CI (지속적 통합)
파이프라인과 구성요소는 커밋되거나 소스 레포지토리로 푸시될 때 빌드, 테스트, 패키징된다.
- 특정 추출 로직을 테스트
- 모델에 구현된 메소드 단위 테스트
- 모델 학습이 수렴하는지 테스트
- 모델 하급에서 0으로 나누거나 작은 값, 큰 값을 조작하여 NaN 값을 생성하지 않는지 테스트
- 파이프라인의 각 구성요소가 예상된 아티팩트를 생성하는지 테스트
- 파이프라인 구성요소간 통합 테스트
CD (지속적 배포)
- 새 파이프라인 구현을 대상 환경에 지속적으로 배포하여 새로 학습된 모델의 예측 서비스를 전달한다.
- 모델 배포 전 모델과 대상 인프라 호환성 확인 (패키지 호환 여부/메모리/컴퓨팅 자원 등)
- 서비스 API 호출 테스트
- QPS 및 지연 시간과 같은 서비스 부하 테스트
7. MLOps 지원도구
- kubeflow: MLOps 지원도구
- 엔드투엔드(End-to-End) AI 플랫폼. 머신러닝 워크플로우의 머신러닝 모델 학습부터 배포 단계까지 모든 작업에 필요한 도구와 환경을 쿠버네티스(Kubernetes) 위에서 쿠브플로우 컴포넌트로 제공
- 머신러닝 워크플로우를 쉽게 구성하고 실행할 수 있도록 도와주는 오픈소스 플랫폼
- 컨테이너: 서버의 한 종류. 용량이 커 효율성을 위해 여러 SW 실행 -> 공간분리 후 안전성 확보 (; 가상화) like 다세대 주택
- 기존 vm머신보다 컨테이너가 가볍고 빠름. 1대의 서버에서 여러 개의 SW를 안전하고 효율적으로 운영할 수 있음.
- 도커: 컨테이너를 만들고 관리해주는 전문가. 컨테이너 관리를 위한 프로그램
- 쿠버네티스: 오픈소스 컨테이너 오케스트레이션 플랫폼. 서버가 여러 대 있는 환경에서 각 서버에 있는 도커에게 대신 지시를 내림

'MLOps' 카테고리의 다른 글
| [MLOps]Vertex AI Pipeline(Kubeflow Pipeline) (0) | 2025.02.24 |
|---|